Abstract
The efficacy of AI agents in research is hindered by their reliance on static, predefined strategies. This creates a critical limitation: agents can become better tool-users but cannot learn to become better strategic planners, a crucial skill for complex domains. We introduce HealthFlow, a self-evolving AI agent that overcomes this limitation through a novel meta-level evolution mechanism. Our agent autonomously refines its own high-level problem-solving policies by distilling procedural successes and failures into a durable, strategic knowledge base.
To anchor our research and facilitate reproducible evaluation, we introduce EHRFlowBench, a new benchmark featuring complex, realistic data analysis tasks derived from peer-reviewed research. Our comprehensive experiments demonstrate that our self-evolving approach significantly outperforms state-of-the-art agent frameworks. This work marks a necessary shift from building better tool-users to designing smarter, self-evolving task-managers, paving the way for more autonomous and effective AI for scientific discovery.
HealthFlow Framework
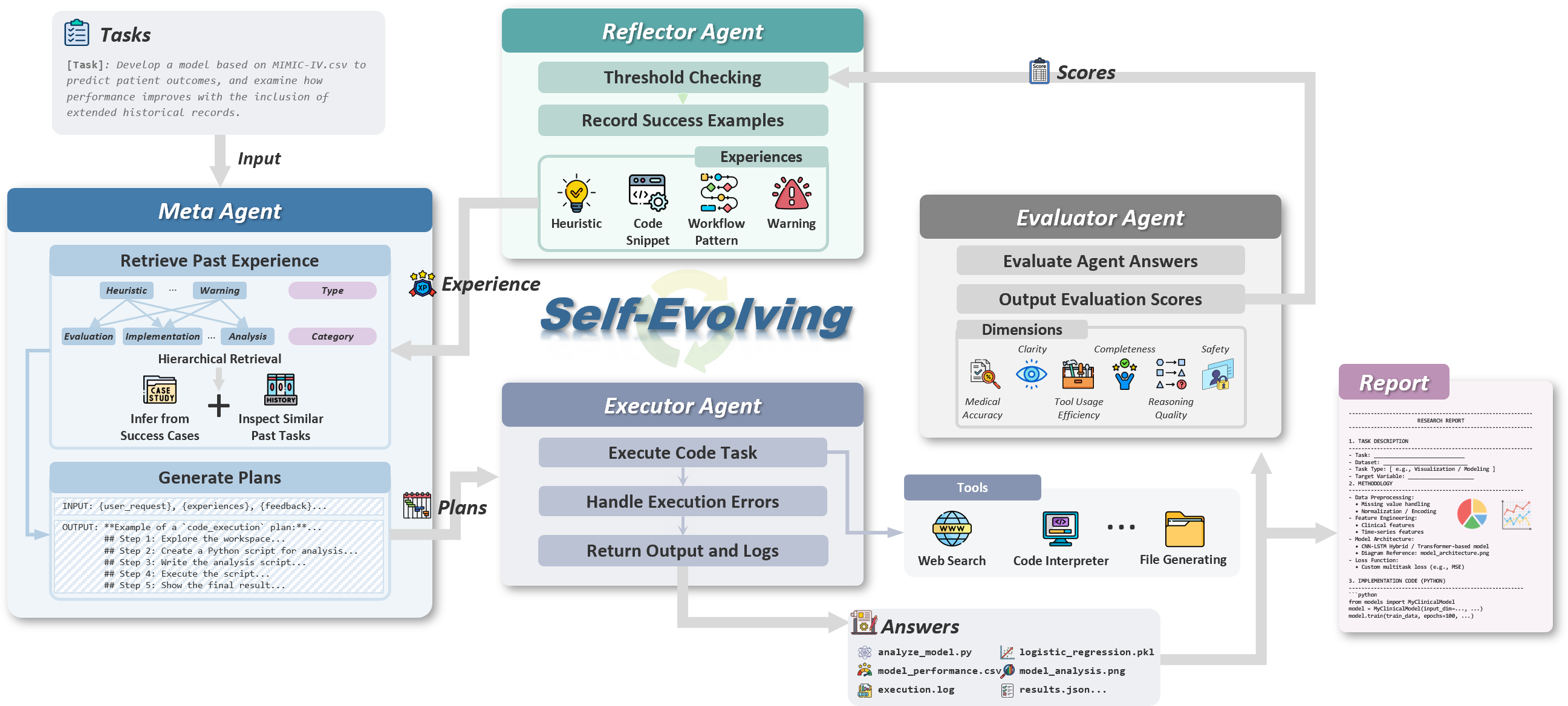
The self-evolving architecture of our framework. It operates in a continuous learning loop. (1) A task is received by the meta agent, which generates a strategic plan by retrieving relevant past experiences. (2) The executor agent executes this plan using tools, producing results and detailed logs. (3) The evaluator agent assesses the execution, providing feedback for short-term correction. (4) Upon success, the reflector agent analyzes the entire process to synthesize abstract experience, which is stored in a persistent memory to augment the meta agent's strategic capabilities for future tasks.
Meta Agent: Strategic Planner
Functions as the cognitive hub, responsible for high-level strategic planning. It translates a user's research request into a concrete, executable plan.
Crucially, its planning is dynamically informed by accumulated knowledge from a persistent experience memory, allowing it to adapt its overarching strategy and evolve over time by incorporating learned best practices and avoiding previously identified pitfalls.
Executor Agent: Execution Engine
A dedicated engine that translates strategic plans into concrete, tool-based operations within a secure, isolated workspace.
It utilizes fundamental tools like a Python interpreter and shell, meticulously recording every command, output, and intermediate file to generate a comprehensive execution log for later analysis and reflection.
Evaluator Agent: Short-term Corrector
Serves as an impartial critic, providing immediate, task-specific feedback to drive iterative improvement within a single task attempt.
It assesses execution artifacts against the original request, producing quantitative scores and qualitative feedback to diagnose failures and guide the meta agent in a tight self-correction loop.
Reflector Agent: Long-term Knowledge Synthesizer
The engine of our framework's long-term, meta-level evolution. Its role transcends the immediate correction of a single task.
After a task is successfully completed, it analyzes the entire execution trace to distill abstract, generalizable knowledge. It synthesizes this analysis into structured experiences—like heuristics, workflow patterns, or code snippets—which are committed to persistent memory to enhance future strategic planning.
Key Results
Dominant Performance on Agentic Benchmarks
- ◆Superior Execution: Our agent significantly outperforms all baselines on complex agentic benchmarks like EHRFlowBench, which require coding, data exploration, and analysis.
- ◆High Win Rate: In head-to-head comparisons, our agent achieves a dominant win rate against all competing frameworks, showcasing its robust capabilities in end-to-end research tasks.
- ◆Competitive Reasoning: On knowledge-intensive QA tasks, our agent performs competitively, matching other leading agents.
The Value of an Evolving Architecture
- ◆Feedback is Crucial: Removing the feedback loop (evaluator & reflector) causes a major performance drop, proving that iterative correction is fundamental to success.
- ◆Experience Provides an Edge: Disabling the long-term experience memory also degrades performance, showing that accumulating strategic knowledge provides a durable advantage over simple trial-and-error.
- ◆"On-the-fly" Learning: The system's ability to learn from new tasks is powerful, demonstrating strong test-time adaptation even without a pre-populated experience memory.
LLM Choice is Critical for Agent Success
- ◆Smarter Planner, Better Outcome: Using a more powerful "frontend" reasoning model for planning and reflection directly translates to better strategic outcomes and higher success rates.
- ◆Execution Fidelity Matters: A high-fidelity "backend" executor model is equally important. Failures in basic instruction-following (e.g., misinterpreting file paths) can cause total task failure, regardless of the plan's quality.
- ◆Separation of Concerns: The optimal setup requires a powerful general reasoner for high-level strategy and a reliable, instruction-following coder for execution.
Experts Overwhelmingly Prefer Our Agent
- ◆Blind Review: In a blind head-to-head comparison, domain experts evaluated solutions from our agent and other leading agents.
- ◆Clear Winner: The expert evaluators overwhelmingly preferred solutions generated by our agent across a diverse set of research tasks.
- ◆Practical Utility: This result validates the practical utility and superior quality of our agent's outputs for real-world research challenges.
Supplementary Materials
Download Full Materials
For the convenience of reviewers, the complete supplementary materials, including the full source code, datasets, and benchmark details, are available for direct download. This avoids the need for external links that could compromise the anonymity of the review process.
Download Supplementary_Material.zipResources
Paper
Read our anonymous submission, which details the agent architecture, the benchmark, and our comprehensive experimental results.
PDF in SupplementaryCode
Access the full source code, including implementations of all agent components and the experience evolution mechanism.
Available in SupplementaryEHRFlowBench
Explore our new benchmark, featuring realistic data analysis tasks derived from peer-reviewed research.
Available in SupplementaryCitation
@article{anonymous2025,
title={{HealthFlow: A Self-Evolving AI Agent with Meta Planning for Autonomous Healthcare Research}},
author={Anonymous Authors},
year={2025},
journal={Submitted for review}
}